
If you've ever worked with sequential data — text, time series, speech, or user behavior — you've probably faced this question: Should I use LSTM or GRU?
At first, they seem almost identical. Both are improvements over traditional RNNs. Both help models "remember" information for longer. Both are widely used in NLP and forecasting tasks.
But once you start building real models, you realize the choice isn't always obvious.
In this guide, we'll break down:
- How LSTM and GRU actually work
- Their architectural differences (with diagrams)
- Real-world use cases
- How to choose between them practically
Why LSTM and GRU Were Introduced
Before LSTM and GRU, we relied on standard RNNs. The idea sounded promising: a neural network that could remember past inputs. But in reality, RNNs had a major flaw.
As sequences got longer:
- Early information faded away
- Gradients became unstable
- The model forgot important context
This is known as the vanishing gradient problem, and it made standard RNNs unreliable for long sequences.
LSTM and GRU were introduced to solve this exact issue — by giving networks a smarter way to manage memory.
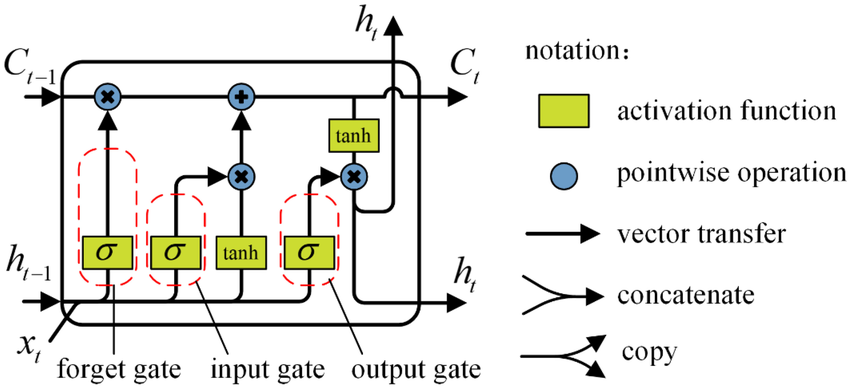
Understanding LSTM (Long Short-Term Memory)
LSTM is designed like a careful memory system. It keeps track of what to remember, what to forget, and what to share.
Instead of letting information pass blindly through time, it uses three gates:
- Forget gate → decides what to erase
- Input gate → decides what new information to store
- Output gate → decides what to pass forward
This allows LSTMs to preserve long-term dependencies much better than simple RNNs.
Why LSTM Works Well
LSTM is especially good at:
- Long sequences
- Complex dependencies
- Context-heavy tasks
However, this comes with trade-offs:
- More parameters
- Slower training
- Higher computational cost
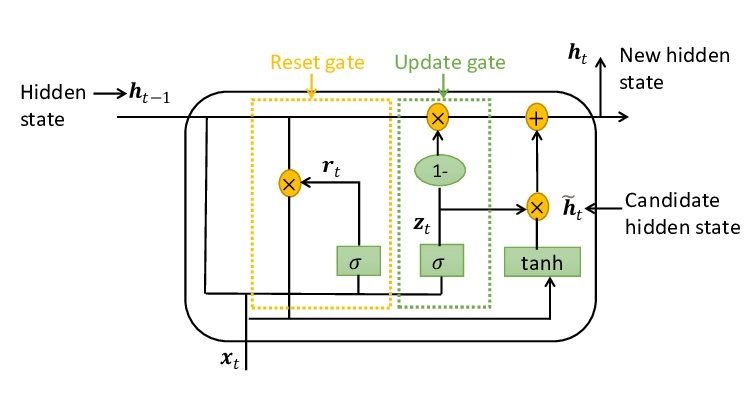
Understanding GRU (Gated Recurrent Unit)
GRU was introduced as a simpler alternative to LSTM.
Instead of three gates, GRU uses:
- Update gate
- Reset gate
It also merges the cell state and hidden state into one structure, making the model lighter and faster.
Why GRU Is Popular
GRU often:
- Trains faster
- Uses fewer parameters
- Performs similarly to LSTM on many tasks
This makes it a strong choice when efficiency matters.
Key Differences Between LSTM and GRU
| Feature | LSTM | GRU |
|---|---|---|
| Gates | 3 | 2 |
| Memory Cell | Separate cell state | No separate cell state |
| Parameters | More | Fewer |
| Training Speed | Slower | Faster |
| Complexity Handling | Better for complex tasks | Good for simpler tasks |
When Should You Use LSTM?
LSTM works best when:
- Sequences are long
- Context matters heavily
- You have enough data
- Training speed is less critical
Common Use Cases
- Machine translation
- Speech recognition
- Document-level NLP
- Complex forecasting
When Should You Use GRU?
GRU is often the better choice when:
- You need faster training
- You have limited data
- The task isn't highly complex
- You want quick experimentation
Common Use Cases
- Sentiment analysis
- Short-text classification
- Real-time predictions
- Smaller datasets
Real-World Insight Most People Don't Talk About: In many practical projects, the performance gap between LSTM and GRU is surprisingly small. You might spend hours debating theory, only to discover both models perform nearly the same on your dataset.
That's why many practitioners:
- Start with GRU
- Move to LSTM if needed
- Let experiments decide
Are LSTM and GRU Still Relevant Today?
Even with Transformers dominating NLP, LSTM and GRU still have advantages:
- Lower computational cost
- Better for small datasets
- Easier deployment
- Strong baselines
They remain useful in:
- Edge devices
- Time-series modeling
- Low-resource environments
Final Thoughts
Choosing between LSTM and GRU isn't about finding a universal winner. It's about choosing the right tool for your problem.
- If you need deeper memory and have the resources, LSTM is powerful.
- If you want speed and efficiency, GRU is often enough.
Most of the time, your dataset will decide which one works best.